Module 7 : Approches méthodologiques et stratégies d’enquête
32 L’approche quantitative et statistique et ses principales stratégies d’enquête
Judicaël Alladatin, Talagbé Gabin Akpo et Mohamadou Salifou
Présentation du thème et des auteurs du chapitre
Ce chapitre porte sur l’approche quantitative. Il fournit des informations importantes pouvant permettre de conduire convenablement la réalisation et l’exploitation d’une enquête par questionnaire. Nous présentons donc les ficelles de la réalisation d’un questionnaire ergonomique, ainsi que les modes d’administration d’un questionnaire. Nous abordons ensuite la notion d’échantillonnage, ainsi que l’épineuse question de la représentativité en approche quantitative. Nous finissons par un exposé sur les stratégies de saisie ou d’enregistrement des données, ainsi que les principales perspectives d’exploitation statistique des données.
Judicaël Alladatin est professeur-chercheur en statistique, administration et gouvernance de l’éducation et de la formation à l’Université Mohammed VI Polytechnique (UM6P) au Maroc. Ses travaux de recherche portent actuellement sur les questions relatives au « faire sens » par les acteurs et actrices de terrain, les transformations et les statistiques en éducation, l’efficacité interne (enseignement-apprentissage) et externe (marché de l’emploi) des systèmes éducatifs, les technologies éducatives et la gouvernance des systèmes éducatifs.
Talagbé Gabin Akpo est doctorant en statistiques-modélisation à l’Université Laval (Québec). Après son master en statistique de l’École Nationale Polytechnique de l’Université Yaoundé I (Cameroun), il a collaboré avec le Centre de recherche sur les maladies tropicales négligées (CRFIlMT) financé par la fondation Bill-et-Melinda-Gates qui l’a conduit à entamer une thèse dans la gestion de la multidimensionnalité des modèles de régression. Son champ de recherches porte sur la régression par copule, l’analyse asymptotique et la modélisation de la dépendance. Il est membre du laboratoire de statistique du Centre de Recherche en Mathématique de l’Université de Montréal.
Mohamadou Salifou est chercheur associé au Groupe d’analyse de la vulnérabilité et des conditions de vie et à la Boutique des Sciences « Siabanni » de Parakou (Bénin) ainsi qu’assistant de recherche à la Chaire Internationale en Physique Mathématique et Applications (CIPMA) de l’Université d’Abomey-Calavi (Bénin). Ses travaux traitent de l’application de l’intelligence artificielle en santé, économie et agriculture et ses champs de recherches portent sur la Data Science, l’Intelligence Artificielle, les méthodes statistiques d’apprentissages supervisés et non supervisés.
Introduction
À la différence des données qualitatives, qui sont des informations littérales provenant le plus souvent d’entretiens individuels et de discussions de groupe, les données quantitatives sont des informations numériques ou statistiques provenant le plus souvent d’enquêtes, de rapports ou de données administratives. Les données quantitatives sont utiles quand on cherche à décrire le qui, le quoi, le où et le quand, afin de fournir un portrait ou les tendances d’une population ou d’une région. Les données qualitatives fournissent, quant à elles, une information enrichie, approfondie sur quelques individus ou quelques cas, et sont donc utiles quand on cherche à expliquer le comment et le pourquoi.
Dans ce chapitre, nous abordons la collecte et l’exploitation des données quantitatives. Il s’agira donc d’étudier le processus de réalisation et d’exploitation d’une enquête par questionnaire. L’enquête par questionnaire regroupe l’ensemble des techniques de collecte qui s’appuient sur la confection et l’utilisation d’un questionnaire, par exemple, le sondage par questionnaire, le questionnaire postal et l’enquête par questionnaire direct. Cette méthode est utilisée lorsque le sujet est relativement bien connu, ou encore lorsqu’on :
- veut des résultats quantifiés;
- cherche à valider et à généraliser les résultats;
- a les moyens de mener une telle enquête;
- peut accéder à la population, c’est-à-dire recevoir suffisamment de réponses et avoir la capacité à traiter les données (argent, temps, logiciel, par exemple).
La mise en œuvre d’une telle opération exige le déroulement de plusieurs étapes :
- Définition de l’objet de l’enquête et de la population cible;
- Pré-enquête d’exploration du sujet (terrain ou documentation);
- Définition finale des objectifs et hypothèses de l’enquête (le cas échéant);
- Définition des indicateurs, confection de l’outil de collecte et plan de sondage;
- Pré-test ou test de l’outil de collecte;
- Formation des enquêteurs et enquêtrices (le cas échéant), préparation du terrain et confection du masque de saisie;
- Collecte des données;
- Plan de codage, dépouillement et saisie des données et finalisation de la base de données;
- Plan d’analyse et analyse des données;
- Rapport provisoire, analyse critique du déroulement (post-enquête) et rapport final.
L’outil de prédilection dans le cadre de la collecte de données quantitatives est le questionnaire, et la méthode d’observation est l’enquête par questionnaire. L’enquête par questionnaire peut apparaître comme une méthode d’observation d’élaboration facile (rapidité, faible coût, anonymat, etc.), mais elle requiert une certaine compétence basée sur une technique sûre. Elle prive, entre autres, le chercheur ou la chercheuse de beaucoup d’observations accessibles lors d’un contact direct. De plus, certains thèmes sensibles sont difficilement abordables dans un questionnaire et des difficultés liées au taux de réponse et au contrôle des non-réponses peuvent se manifester.
En dehors de l’enquête par questionnaire, le sondage peut parfois être utilisé dans le cadre de la collecte de données quantitatives. En statistiques, un sondage est une enquête réalisée sur une population donnée, humaine ou non, pour en mesurer ses caractéristiques concernant un sujet précis. Il est réalisé selon une méthode statistique auprès d’un échantillon représentatif de la population.
Du sujet de recherche au questionnaire ergonomique
Le questionnaire est un document imprimé ou électronique destiné à recueillir les données requises par un protocole de recherche[1]. Cet outil vise la collecte structurée et standardisée de données en accord avec le protocole de recherche et la règlementation. Plusieurs types de questions peuvent permettre de varier le questionnaire :
- Des questions ouvertes : par exemple, quelle est, à votre avis, la meilleure méthode d’apprentissage de la lecture?
- Des questions à choix multiples : par exemple, quelle est la méthode d’apprentissage de la lecture que vous utilisez actuellement dans votre classe? Le syllabaire [], l’analytique [], la gestuelle [], la fonctionnelle [].
- Des questions semi-ouvertes : par exemple, pour quelles raisons n’utilisez-vous pas la méthode gestuelle? Elle est trop complexe [], il n’existe pas de bons manuels [], je la trouve peu efficace [], autre raison à préciser [].
- Des échelles de mesure : par exemple, utilisez-vous un manuel de lecture pour vos élèves? Fréquemment [], Souvent [], Rarement [], Jamais [].
- Des questions fermées : par exemple, êtes-vous d’accord pour l’usage de la méthode gestuelle comme méthode pédagogique prépondérante? oui [], non [].
Le processus d’élaboration de questionnaire comporte plusieurs étapes :
- Définir les dimensions et les sous-dimensions de l’étude à partir du sujet, de la problématique, des objectifs et hypothèses, mais aussi de l’exploration (pré-enquête);
- Identifier les questions reliées à chaque indicateur;
- Rédiger le questionnaire (formulation et mise en forme);
- Relire le questionnaire (relecture multidisciplinaire, par exemple, par un-e statisticien-ne, sociologue, démographe, agronome);
- Pré-test auprès de la population à l’étude et corrections;
- Rédaction du guide de l’enquêteur ou de l’enquêtrice et du formulaire de consentement, s’il y a lieu.
Le questionnaire
Le questionnaire est un instrument de mesure soumis à des erreurs de mesure, des erreurs du ou de la répondant-e, des erreurs de l’enquêteur ou de l’enquêtrice, ou encore des erreurs liées à la manière de coder l’information. Il est donc important de passer du temps sur la forme et le fond du questionnaire (ergonomie). Cela suppose que le questionnaire doit être fidèle, valide, pertinent et neutre. Il faut en outre faire attention aux points suivants :
- Pré-codage, alignement à droite, utilisation de tableaux, etc.;
- Respect de l’ordre numérique et chronologique;
- Regrouper ensemble ce qui va ensemble;
- Tenter de garder le questionnaire intéressant et attrayant pour les répondant-e-s du début à la fin, entre autres en variant les styles de questions (désirabilité sociale);
- Respecter le cheminement normal d’une conversation.
Le questionnaire ne doit pas être long pour ne pas lasser, mais doit fournir suffisamment d’information. L’ordre des questions peut jouer un rôle important, car une question peut en influencer une autre, ce qu’on appelle l’« effet de contamination ». Il faut vérifier cela en pré-test et, le cas échéant, varier l’ordre des questions. Parfois, il est préférable de mettre les éléments socio-démographiques en fin de questionnaire pour éviter l’effet de contamination. Enfin, il est important de soigner, dans le questionnaire, le mot de présentation et de fin.
En ce qui concerne la formulation de chaque question, plusieurs règles doivent être respectées :
- Éviter les termes polysémiques, le langage ou vocabulaire trop technique ou trop élaboré. Exemple : Pensez-vous que les réfugié-e-s sont victimes d’exclusion sociale sur leur terre d’accueil?
- Formuler des questions bien ciblées et discriminantes pour ne pas avoir des questions pour lesquelles tout le monde répond « oui ». Au lieu de demander simplement : « Pensez-vous que l’école est importante de nos jours? », une façon de mieux cibler la réponse serait de demander : « Estimez-vous qu’il est acceptable de délaisser l’école primaire ou secondaire au profit d’une activité génératrice de revenus? »;
- Éviter les questions qui ne répondent à aucun objectif;
- Éviter les questions trop longues;
- Veiller au mieux à la pré-codification;
- La question doit être comprise à la première lecture, car les personnes qui vont y répondre ne lisent pas forcément attentivement;
- Éviter les questions imprécises (par exemple, la notion de mariage, en Afrique, revêt plusieurs formes et peut même regrouper les unions libres ou le concubinage selon le point de vue de l’enquêté-e. Si l’objectif de la question est de mesurer la fréquence des mariages civils, la question « Êtes-vous marié-e? » s’avère ainsi imprécise dans un tel contexte);
- Éviter les adverbes indéfinis (près, régulièrement, prochainement, etc.);
- Éviter les mots extrêmes (souvent, beaucoup, tout. etc.);
- Éviter les mots qui n’ont pas le même sens pour tous et toutes;
- Éviter les termes trop généraux;
- Éviter les exemples trop spécifiques;
- Éviter les questions tendancieuses qui influencent la réponse (donc par exemple);
- Faire attention aux mots chargés émotionnellement (liberté, égalité, justice, décès).
Exemple avec la variable « Soutien social » :
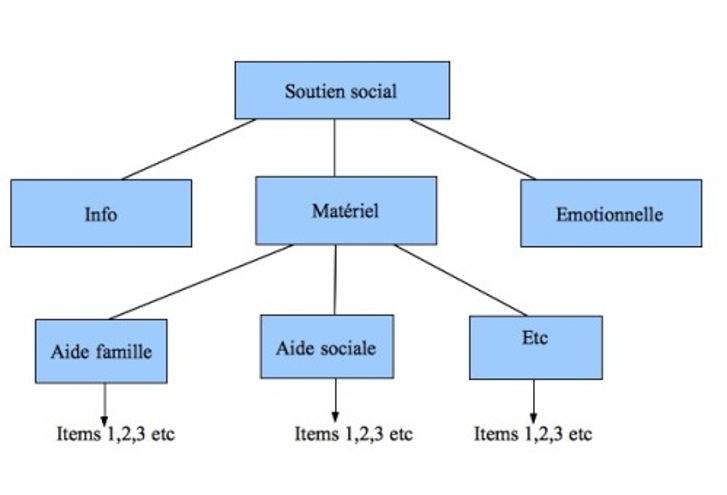
Mode d’administration du questionnaire
Il existe globalement trois modes d’administration du questionnaire.
- Le mode direct : il s’agit d’un contact humain direct, soit par porte-à-porte soit par sondeurs ou sondeuses dans la rue, où l’enquêteur ou l’enquêtrice pose les questions et enregistre les réponses fournies (attention à leur formation/motivation qui a un impact important).
- Le mode indirect : il s’agit d’un contact humain indirect effectué par le biais d’un centre d’appel (établir un protocole précis).
- L’auto-administration : il s’agit ici d’un questionnaire papier ou électronique à remplir par l’enquêté-e et à renvoyer par le biais de la poste, d’un courriel ou d’un système informatisé. Lorsque la réponse de l’enquêté-e est envoyée par courriel, on parle de DED (déclaration électronique des données) ou de CAWI (Computer-Assisted Web Interviewing) s’il s’agit d’un système informatisé. Certains outils informatiques facilitent l’utilisation de CAWI, dont le Sphinx Online ( système « pro ») et Google Forms (gratuit).
Dans le cadre de l’administration du questionnaire, il faut faire attention aux éléments suivants :
- Les règles éthiques et déontologiques (Genard & Roca, 2014);
- L’effet de contexte : faire attention aux circonstances dans lesquelles les participants et participantes répondent;
- Préparer préalablement le terrain;
- Veiller au suivi du processus de recrutement et formation des personnes qui vont réaliser l’enquête;
- Choisir le mode d’administration adapté (temps, compétence et budget).
Échantillonnage
La recherche quantitative repose sur l’analyse des données numériques obtenues à partir d’une investigation empirique effectuée par soi-même (données primaires) ou d’une base de données existante (données secondaires). Il est donc important de se demander s’il est préférable de collecter les données soi-même ou d’obtenir les informations dont on a besoin d’une base de données existante. Dans le premier cas, les données doivent être collectées au moyen de techniques de collecte de données acceptées afin de protéger la crédibilité et la fiabilité des résultats de la recherche.
L’idéal serait de réaliser une enquête exhaustive pour collecter les données sur l’ensemble de la population d’étude. Cependant, ce type d’enquête est très coûteux et dure sur une longue période pouvant excéder le cadre de la thèse ou du mémoire. Ainsi, les enquêtes sont pour la plupart réalisées par sondage, ce qui consiste à collecter les données auprès d’une fraction de la population mère. Cette technique offre l’avantage, lorsqu’elle utilise des méthodes valides, d’extrapoler les résultats à l’ensemble de la population. Pour cela, il est essentiel de choisir soigneusement l’échantillon afin qu’il soit le plus représentatif que possible de la population mère (Fortin & Gagnon, 2016).
L’échantillonnage est le procédé par lequel l’on sélectionne un échantillon d’étude au sein d’une population dans le cadre d’une enquête par sondage. Le graphique suivant résume les différentes étapes de la phase d’échantillonnage.
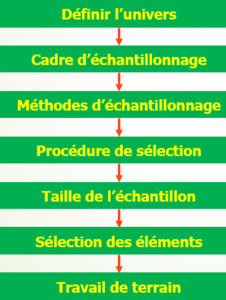
En matière d’échantillonnage, le souci permanent en statistique est, d’une part, l’effectif et, de l’autre, la représentativité. Même si l’on reconnait que plus la taille de l’échantillon est grande, plus la marge d’erreur est atténuée, il faut garder à l’esprit qu’une taille élevée ne garantit pas une représentativité de l’échantillon. L’échantillon est dit représentatif lorsque les résultats qu’il fournit sont sensiblement les mêmes que dans le cadre d’une étude exhaustive. C’est donc la méthode d’échantillonnage qui détermine le plus la représentativité et non la taille de l’échantillon.
Dans le cadre d’une étude où l’on cherche à contrôler la marge d’erreur et l’intervalle de confiance, la taille de l’échantillon est déterminée par la formule :

- n est la taille théorique souhaitée;
- α (s) est le seuil de confiance (ou niveau de confiance ou encore taux de confiance) que l’on souhaite garantir sur la mesure;
- Zα (t), le coefficient de marge déduit du taux de confiance (1,96 quand α = 95%);
- e (m), la marge d’erreur que l’on se donne pour la grandeur que l’on veut estimer (par exemple, on veut connaître la proportion réelle à 5% près).
- p est la proportion attendue de la caractéristique qui nous intéresse (c’est-à-dire, les réponses des personnes répondantes à certaines questions) et dont on veut contrôler la marge d’erreur. On prend habituellement la proportion maximale, soit 0,5.
- 1-p est 1 moins la proportion p.
Dans le cas d’une population de petite taille, on constate que n est supérieur à N. Il faut alors procéder à une correction en déterminant n’ (taille corrigée de l’échantillon) avec la formule suivante :

Il existe plusieurs types d’échantillonnage, dont probabiliste et non probabiliste.
L’échantillon probabiliste
Les méthodes probabilistes sont basées sur un processus de sélection aléatoire des individus (accessibles ou non). Cela veut dire que chaque individu de la population d’étude a une chance égale ou non nulle d’être sélectionné pour faire partie de l’échantillon d’étude. Ce faisant, les méthodes probabilistes présentent l’avantage d’obtenir un échantillon représentatif et d’extrapoler les résultats à l’ensemble de la population. La mise en œuvre de ces méthodes nécessite une base de sondage. La base de sondage est la liste exhaustive de tous les individus de la population d’étude.
Échantillonnage aléatoire simple est une technique de sélection des éléments de l’échantillon d’étude qui offre à chacun d’eux la même chance d’en faire partir. Dans ce cas, la probabilité pour qu’un élément soit sélectionné est donnée par la formule suivante :![]() avec n comme taille de l’échantillon et N celle de la population mère. L’échantillonnage aléatoire simple permet de corriger des biais d’échantillonnage et d’évaluer l’erreur d’échantillonnage (Fortin & Gagnon, 2016). Il favorise la représentativité de l’échantillon d’étude, mais ne la garantit pas.
avec n comme taille de l’échantillon et N celle de la population mère. L’échantillonnage aléatoire simple permet de corriger des biais d’échantillonnage et d’évaluer l’erreur d’échantillonnage (Fortin & Gagnon, 2016). Il favorise la représentativité de l’échantillon d’étude, mais ne la garantit pas.
Échantillonnage stratifié consiste à subdiviser la population d’étude en des groupes exclusifs (homogènes) appelés strates et à tirer aléatoirement à l’intérieur de chaque strate. Les critères de stratification dépendent du chercheur ou de la chercheuse et de ses objectifs. Il est possible de créer les strates en utilisant le critère du découpage géographique comme la zone dénombrement (ZD), la commune ou la région.
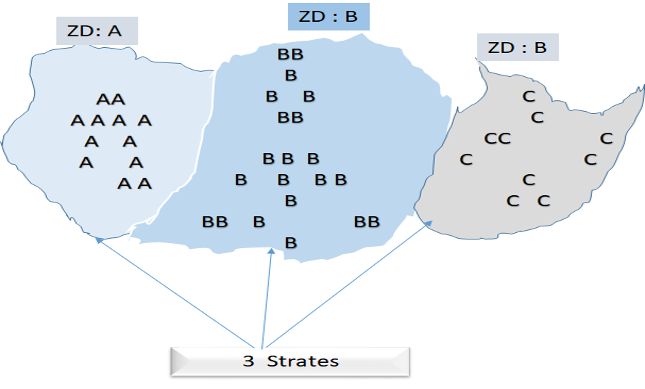 On peut également utiliser comme critère l’une des caractéristiques (sexe, profession, etc.) connues de la population d’étude. Cette technique de sélection des individus présente l’avantage d’apporter des précisions par strate.
On peut également utiliser comme critère l’une des caractéristiques (sexe, profession, etc.) connues de la population d’étude. Cette technique de sélection des individus présente l’avantage d’apporter des précisions par strate.
Échantillonnage systématique obéit à une règle simple, dans laquelle chaque k-ième unité est sélectionnée à partir d’un nombre de 1 à k choisi au hasard comme point de départ aléatoire. Cette méthode consiste à dresser la liste de tous les éléments de la population d’étude et de déterminer le pas d’échantillonnage k en divisant la taille de population par la taille de l’échantillon. Ensuite, on détermine le point de départ en choisissant aléatoirement entre 1 et le pas k. On sélectionne enfin chaque k-ième unité jusqu’à atteindre le nombre d’unités voulues pour former l’échantillon.
Échantillonnage hiérarchique (ou échantillonnage à plusieurs degrés) consiste à identifier et sélectionner aléatoirement au premier degré les sous-groupes de la population. Après, on échantillonne à l’aide d’une technique probabiliste les unités au sein des sous-groupes sélectionnés au second degré.
L’échantillonnage non probabiliste
Contrairement aux méthodes probabilistes, la mise en œuvre des méthodes non probabilistes n’obéit à aucune règle de hasard. Les méthodes non probabilistes sont plutôt définies selon des critères de faisabilité, de ressemblance à la population cible et de critères subjectifs dépendant du choix des enquêteurs et enquêtrices.
De convenance : le choix de l’échantillon d’étude repose sur les commodités. Le chercheur ou la chercheuse sélectionne les individus qui sont à sa portée, en raison des contraintes d’accessibilité, de la praticité et du coût.
De jugement : encore appelée échantillonnage par choix raisonné, cette technique d’échantillonnage non probabiliste est basée sur le jugement du chercheur ou de la chercheuse par rapport à certaines caractéristiques de la population.
Boule de neige : les unités de l’échantillon sont sélectionnées à travers des réseaux d’amitié en fonction des liens d’amitié des individus sélectionnés avec un noyau d’individus.
Par quota : les unités sont sélectionnées de façon accidentelle, mais avec un quota à atteindre. On peut demander à l’enquêteur ou l’enquêtrice de se mettre sur un carrefour et d’enquêter 10 hommes et 15 femmes.
Volontaire : l’échantillon est constitué sur la base des volontaires. 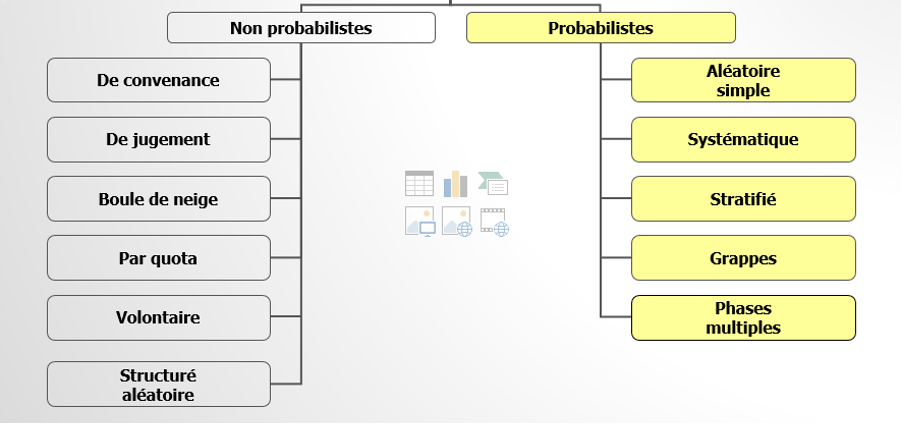 Retrouvez plus de détails sur ces différentes méthodes dans le cours de Christine Dufour et Vincent Larivière (2012)[2] et le document de Marie-Fabienne Fortin (2010)[3].
Retrouvez plus de détails sur ces différentes méthodes dans le cours de Christine Dufour et Vincent Larivière (2012)[2] et le document de Marie-Fabienne Fortin (2010)[3].
Saisie des données et exploitation statistique
Pour effectuer la saisie des données, il faut disposer d’un masque de saisie. Le masque de saisie est un modèle électronique du questionnaire, définissant les zones de saisie (champs), leur type (numérique, date, caractères, etc.), ainsi que les contrôles de saisie (contraintes sur l’ordre de saisie et des valeurs qui peuvent être renseignées). Plusieurs logiciels permettent de concevoir des masques de saisie : CSPro, ÉpiInfo, Excel, SPSS ou encore Accès (saisie décentralisée).
Il est important de procéder à une bonne organisation de la saisie des données en veillant au matériel utile, au personnel nécessaire ainsi qu’au suivi quotidien des agent-e-s de saisie. Exemple :
Si la taille de l’échantillon de l’enquête est de 4 500 ménages, et chaque ménage prend en moyenne 20 minutes de saisie, le temps nécessaire pour la saisie de l’ensemble des ménages est de 1 500 heures. Si chaque agent-e de saisie travaille 40 heures par semaine et si vous avez 8 semaines pour achever la saisie des données, vous aurez besoin de 5 ordinateurs et de 5 agent-e-s. Il arrive parfois qu’une équipe de deux agents de saisie travaillent sur le même ordinateur. Chaque agent-e pourrait travailler pendant 6 heures, de telle sorte qu’un ordinateur soit employé pendant 12 heures par jour.
Il est préférable de commencer la saisie des données pendant que les enquêteurs et enquêtrices sont sur le terrain. Ceci permet de repérer et de corriger des erreurs que certain-e-s enquêteurs, enquêtrices ou équipes peuvent commettre. Les problèmes sérieux qui peuvent échapper à l’attention du superviseur ou de la superviseuse de terrain peuvent ainsi être détectés rapidement, suffisamment tôt pour reprendre la formation du personnel de terrain et corriger les erreurs importantes.
Les figures suivantes montrent diverses modalités d’organisation de la saisie des données.
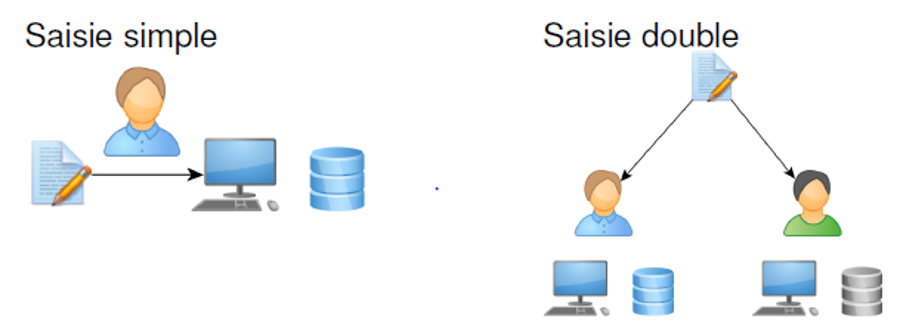

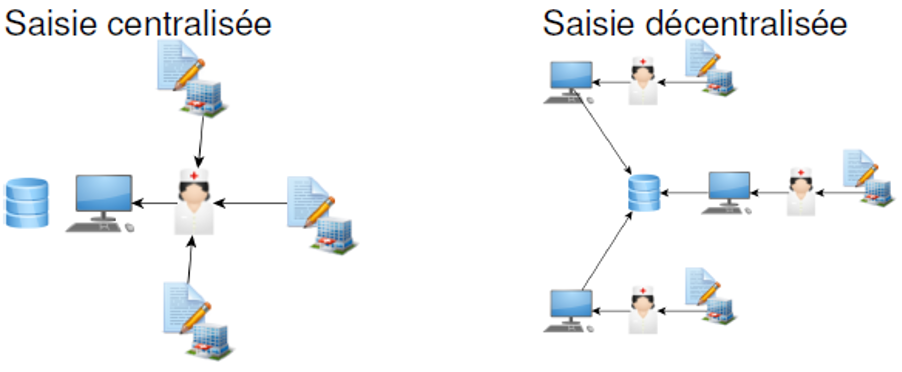 Après l’opération de collecte de données, il est important de réaliser un feedback et un bilan sur le déroulement de l’enquête. Cela permet de contrôler les phénomènes parasites (effet enquêteur/enquêtrice, effet répondant-e).
Après l’opération de collecte de données, il est important de réaliser un feedback et un bilan sur le déroulement de l’enquête. Cela permet de contrôler les phénomènes parasites (effet enquêteur/enquêtrice, effet répondant-e).
Il faut ensuite finaliser la codification notamment au niveau des questions ouvertes ou des questions donnant lieu à de nouvelles modalités. À cet effet, il faut transformer les modalités en codes alphanumériques (ceci peut être fait dès la conception du questionnaire). Il faut aussi prévoir un code pour l’absence de réponse et respecter certaines conventions.
Exemple :
Homme=1, Femme=2
Oui=1, Non=0 ou Oui=O, Non=N (mais attention au mélange de la lettre O et du nombre 0).
La saisie des données exige une certaine concentration. En général, les agent-e-s de saisie ne doivent pas quitter leurs machines alors qu’ils et elles sont au milieu de la saisie d’une fiche. Avant de prendre un temps de repos ou d’arrêter le travail pour la journée, tout le questionnaire en cours doit être complètement saisi. Les données peuvent être saisies sur le disque dur de l’ordinateur et puis transférées (sur une disquette, par exemple) sous forme non apurée au superviseur ou à la superviseuse pour qu’il ou elle en prenne copie sur son ordinateur.
Il est important de minimiser les erreurs de saisie des données autant que possible durant cette phase. Une façon très efficace d’accomplir cela est la saisie double des questionnaires par deux agent-e-s différent-e-s. Les deux fichiers sont ensuite comparés pour incohérences, et ces incohérences sont corrigées. Une autre approche consiste à saisir les données une seule fois, mais à procéder à un certain nombre de vérifications pour éviter les erreurs au moment de la saisie : c’est la saisie intelligente. Quand les données d’une fiche sont saisies, le programme procède à un contrôle d’étendue, de passage et de cohérence : c’est le contrôle de données. Ceci garantit, pour une rubrique donnée qu’aucune valeur saisie n’est en dehors de l’étendue donnée des réponses pour cette rubrique, que le nombre correct d’enregistrements est saisi, que les étendues correctes sont saisies et qu’il y a cohérence interne des données.
Dans le cas où on ne dispose pas de ce genre de procédure de saisie intelligente, une fois donc que l’ensemble des données est saisi, il faut réaliser le contrôle de qualité (tri à plat, par exemple) et nettoyer la base de données (apurement des données). L’expérience a montré, par exemple, que plusieurs erreurs d’étendue sont des erreurs de saisie et qu’il peut être très utile de les contrôler et de les corriger si le contrôle des données est bien réalisé. Il s’agit d’identifier les données aberrantes et de traiter (ou gérer) les valeurs manquantes pour préparer le jeu de données à l’analyse.
Traitement des valeurs manquantes
Les valeurs manquantes ne doivent pas être ignorées lors d’une analyse statistique. Il faut leur accorder une attention particulière en utilisant des moyens de traitement en fonction de leur proportion et leur type.
On distingue principalement deux méthodes de traitement de valeurs manquantes, vous pouvez choisir de les supprimer ou de les imputer. Mais avant toute opération il important de se demander les motifs des valeurs. Les valeurs manquantes sont-elles distribuées aléatoirement? Les valeurs manquantes sont-elles liées à des valeurs d’une variable (les sauts dans le questionnaire).
La suppression des données manquantes se rapporte à deux méthodes. La première méthode consiste à ne considérer que les individus pour lesquels toutes les informations sont disponibles. On supprime du jeu de données les individus pour lesquels on observe des valeurs manquantes. Pour éviter de supprimer trop d’individus, il est possible de faire la suppression par variables (deuxième méthode). C’est ce qui est fait automatiquement avec certains logiciels statistiques, tels que Stata, R. Les lignes comportant des valeurs manquantes lors d’une tabulation sont automatiquement supprimées (si rien n’est précisé). Ainsi la taille de l’échantillon varie d’une variable à une autre. Lorsque les valeurs manquantes sont dues à des sauts au niveau du questionnaire, il est préférable d’utiliser cette méthode.
Quelques méthodes d’imputation des valeurs manquantes
Il existe plusieurs méthodes d’imputation de valeurs manquantes. Les plus utilisées sont :
- Complétion stationnaire : consiste à affecter aux valeurs manquantes la valeur la plus fréquente (le mode de la série).
- Méthode des plus proches voisins : affecte aux valeurs manquantes la valeur moyenne de ses voisins. Elle consiste à identifier (classification) un groupe d’individus le plus proche que possible des individus qui présentent des valeurs manquantes et à affecter en suite la valeur moyenne des individus de ce groupe.
- Complétion par une combinaison linéaire : consiste à remplacer les valeurs manquantes par une combinaison linéaire des observations. Cette méthode est utilisée pour les variables quantitatives. Comme exemple, on peut remplacer les valeurs manquantes par la moyenne (imputation par la moyenne) ou par la médiane (imputation par la médiane). L’inconvénient de cette approche est qu’elle conduit à une sous-estimation de la variance.
Une fois que les corrections concernant les incohérences ont été effectuées et que les imputations sont faites, les données sont « nettoyées » et la base est prête pour l’analyse. La base de données peut donc être soumise aux analyses diverses. À cet effet, on utilise entre autres méthodes la statistique descriptive, la statistique inférentielle et les méthodes avancées. L’analyse des données doit permettre de répondre à la question principale de recherche (aux questions spécifiques évidemment). On peut utiliser à cet effet des tableurs comme Excel ou des logiciels comme SAS, STATA, SPSS, R, etc. Enfin, il est recommandé de réaliser une analyse critique de l’ensemble du processus de collecte et d’exploitation des données.
Analyse statistique de données quantitatives
Il s’agit de résumer l’information contenue dans la base de données avec des méthodes et outils statistiques. Dans la base de données, chaque question renvoie à une variable quantitative ou qualitative. La description d’une variable ou la mise en relation de deux ou plusieurs variables en fonction de la nature de ces dernières (quantitative continue, nominale, ordonnée).
Les tris à plat
Il est question ici de synthétiser les informations d’une variable dans un graphique ou un tableau. Lorsque la variable est nominale, on représente les modalités par ordre décroissant des choix afin de mettre le mode en valeur. Dans le cas des variables ordinales, en revanche, l’ordre des modalités sera respecté dans la présentation puisqu’il répond à une logique. Lorsque la variable est quantitative, continue, en plus d’utiliser les paramètres de tendance et de dispersion, on peut également recoder les données en catégories pour une représentation graphique.
Les mesures de tendance centrale permettent de résumer un ensemble de données relatives à une variable quantitative. Elles permettent de déterminer une valeur « typique » ou centrale autour de laquelle des données ont tendance à se rassembler.
- La moyenne
L’indicateur le plus couramment utilisé est la moyenne empirique ou arithmétique.
La moyenne arithmétique s’écrit :
- La médiane
La médiane, quantile d’ordre 2, est un indicateur de tendance centrale plus robuste que la moyenne. Elle divise la population en deux de sous-groupes de même effectif.
La médiane Me d’une variable X dont les valeurs observées ont été rangées dans l’ordre croissant, se définit comme suit, avec N comme effectif total :
 |
si N est pair |
| si N est impair |
- Le mode
Enfin, un indicateur de position souvent utilisé dans le cas d’un caractère discret est le mode, défini comme la valeur la plus fréquente dans la série d’observations. Pour une variable continue, cette notion ne s’applique pas directement, mais on peut définir une classe modale, lorsque les données ont été préalablement catégorisées.
Un paramètre de dispersion est un indice du degré d’étalement des données qui rend compte de leur variation, le plus souvent par rapport à la moyenne. Entre autres mesures de dispersion, on retient principalement l’étendue, la variance, l’écart-type et le coefficient de variation.
- Étendue
C’est la différence entre la grande et la plus petite observation d’une distribution donnée. Cependant, elle ne donne aucune information sur la distribution de la fréquence des valeurs ni sur la concentration de la plupart d’entre elles. La variance et l’écart-type fournissent cette information.
- Variance
La variance représente la valeur globale de dispersion des observations par rapport à la moyenne.
La variance dans une population s’écrit :![]() .
.
La variance d’un échantillon de taille n s’écrit par contre comme suit : .
.
L’écart-type est égal à la racine carrée de la variance et prend donc la même unité que les observations. Plus grand est l’écart-type, plus les observations sont écartées de la moyenne. Inversement, plus petit est l’écart-type, plus les données se concentrent autour de la moyenne.
- Coefficient de variation
Le coefficient de variation est une autre mesure qui sert à comparer deux distributions de fréquences. Il s’agit d’une mesure relative de dispersion qui permet d’évaluer l’homogénéité des données d’une distribution. Plus le coefficient de variation (Cv) est faible, plus les données sont homogènes, et plus il est élevé moins elles le sont. Le coefficient Cv de variation s’écrit : ![]()
Les tris croisés
Les tris croisés permettent de faire des analyses de la répartition de la population d’étude selon deux variables prises simultanément. Ces variables sont présentées dans des tableaux croisés ou des graphiques qui offrent la possibilité d’examiner la distribution conjointe des deux variables et font apparaître les associations (relations) entre elles. Les méthodes d’appréciation de la relation entre deux variables sont divergentes selon la nature des variables en jeu.

L’analyse des résultats consistera à mettre en relation les variables et comparer les résultats obtenus avec ceux qu’on attendait au moment de la formulation des hypothèses.
Analyses multivariées
L’analyse multivariée désigne un ensemble de méthodes et de techniques destinées à synthétiser l’information issue de plusieurs variables pour décrire la population d’étude ou expliquer un phénomène. Les méthodes d’analyse multivariée sont diverses selon l’objectif de la recherche et la nature des variables présentes dans la base de données. On distingue deux grandes familles de méthodes d’analyse multivariée : méthode descriptive et méthode explicative.
Les méthodes descriptives visent à résumer l’information contenue dans plusieurs variables, sans privilégier l’une d’entre elles en particulier. Les méthodes descriptives les plus utilisées sont :
- Analyse en composante principale (ACP) : applicable sur un ensemble de variables quantitatives;
- Analyse factorielle des correspondances (AFC) : applicable sur deux variables qualitatives;
- Analyse en correspondances multiples : applicable sur un ensemble de variables qualitatives (ou quantitatives);
- Classification.
Les méthodes explicatives quant à elles expliquent un phénomène ou les variations d’une variable (variable à expliquer) par un ensemble de variables (variables explicatives) présentes dans la base de données. Le tableau ci-après présente quelques méthodes usuelles en fonction de la nature des variables.

Bibliographie commentée
Gauthier, B. (1992). Recherche sociale. De la problématique à la collecte des données (2e éd.). Presses de l’Université du Québec.
Cet ouvrage est une source d’information et de réflexion sur l’approche contemporaine de la recherche sociale couvrant la recherche en sciences sociales, l’établissement de la problématique jusqu’à la collecte des données.
de Singly, F. (2012). Le questionnaire. L’enquête et ses méthodes (3e éd.). Armand Colin.
L’auteur répond dans cet ouvrage à deux questions indissociables : à quoi servent les enquêtes par questionnaire? Comment produire de « bons chiffres? »
Granai, G. (1967). Techniques de l’enquête sociologique. Dans G. Gurvitch (dir.), Traité de sociologie (p. 135-151). Presses Universitaires de France.
En distinguant les techniques d’enquête de la méthode globale que constitue la recherche sociologique, Granai fait la part de la démarche conceptuelle et stratégique et la part des procédés utilisés pour recueillir et analyser les données empiriques servant plus ou moins à tester, compléter et corriger les hypothèses.
Howell, D. C. (2008). Méthodes statistiques en sciences humaines (2e éd.). De Boeck.
Cet ouvrage fournit une compréhension conceptuelle maximale de l’ensemble des techniques statistiques communément utilisées en sciences sociales et dans les sciences du comportement; il allie un ton engageant à la rigueur scientifique.
Martin, O. (2005). L’analyse de données quantitatives. L’enquête et ses méthodes. Armand Colin.
Martin répond dans ce livre avec clarté et rigueur aux questions majeures que se pose tout concepteur ou conceptrice d’enquête par questionnaire et expose sans formalisme mathématique les raisonnements statistiques et des arguments probabilistes.
Quivy, R. et Van Campenhoudt, L. (2011). Manuel de recherche en sciences sociales (4e éd.). Dunod.
Les auteurs de cet ouvrage décomposent les différentes étapes de la recherche en sciences sociales, offre un panorama complet et actualisé des techniques et méthodes disponibles et propose enfin de nombreux travaux d’application.
Genard, J.-L. et Roca i Escoda, M. (2014). Les dispositions éthiques dans la conduite de l’enquête et la livraison publique de ses résultats. SociologieS. https://doi.org/10.4000/sociologies.4720
À travers ce texte, les auteurs proposent une réflexion aux liens, souvent sous-estimés quand ce n’est pas tu, entre épistémologie, méthode et éthique.
- En anglais, on parle de « Case Report Form », soit CRF ou eCRF. ↵
- http://reseauconceptuel.umontreal.ca/rid=1J3BCT9WW-NJP6NT-8VW/sci6060_fiche_echant.pdf ↵
- http://www.cheneliere.info/cfiles/complementaire/Fondements_et_etapes_du_processus_de_recherche_2e_edition_9782765025818/exercices/3142-W-Module_2_Exercices.pdf ↵
