26 Les bibliothèques numériques et leurs données : enjeux pour la recherche et l’enseignement
Lyne Da Sylva
Les bibliothèques numériques ont été définies ainsi : « un ensemble de ressources numériques et technologies associées pour créer, repérer et utiliser l’information; les bibliothèques incluent des données, métadonnées et liens (métadonnées) vers d’autres ressources » (Borgman 2000, 42, notre traduction). Elles ne sont pas limitées aux collections de type bibliothéconomique, mais peuvent inclure des ressources de types très différents : des collections archivistiques ou muséales, par exemple, mais aussi des inventaires de ressources pédagogiques ou des données de recherche. Un grand éventail de types est présenté dans Da Sylva (2013). On y mentionne notamment des collections de périodiques numériques (comme Érudit[1] ou Persée[2]), de livres numérisés (comme Les Classiques des sciences sociales[3] ou le Projet Gutenberg[4]), d’images fixes ou en mouvement (comme celles des collections de l’Institut national de l’audiovisuel, en France[5]). Elles incluent également les musées numériques (comme Europeana[6] ou le Musée virtuel de la Nouvelle-France[7]), les archives numériques (par exemple, Canadiana[8]) ainsi que les dépôts institutionnels.
Les travaux de recherche et de développement sur les bibliothèques numériques se sont multipliés au cours des vingt dernières années, et plusieurs aspects des technologies utilisées ont atteint leur maturité. Il est intéressant de se poser la question maintenant : qu’est-ce qui anime dorénavant les efforts de développement?
Ce texte s’appuie sur une recension des travaux récents sur les bibliothèques numériques, soit les congrès et colloques spécialisés, et les revues principales, pour identifier certaines tendances importantes. Nous nous attardons particulièrement sur un aspect d’actualité et qui touche le web sémantique, soit l’introduction des données liées (Linked Open Data) dans les infrastructures des bibliothèques numériques. Nous explorons ensuite certaines des conséquences à prévoir pour les bibliothèques numériques elles-mêmes ainsi que pour ceux et celles qui les créent et les utilisent. Nous précisons au passage les impacts spécifiques sur la bibliothèque numérique Les Classiques des sciences sociales.
Recension sélective d’écrits récents
La genèse et l’évolution des bibliothèques numériques ont déjà été documentées dans Beaudry (2008) et Da Sylva (2013). Ce dernier article fait état des aspects technologiques, économiques et juridiques ainsi que diverses questions liées aux usages des bibliothèques numériques; il résume ainsi les préoccupations de ce moment-là. Pour appuyer notre analyse de la situation actuelle, nous faisons un survol des travaux récents publiés dans les revues pertinentes et des communications présentées lors des colloques principaux dédiés aux bibliothèques numériques, afin d’identifier les nouveautés.
Articles de revues
Un numéro spécial d’une revue témoigne de préoccupations actuelles, sur des thématiques précises qui rassemblent un nombre important de chercheurs et chercheuses. C’est pourquoi nous avons privilégié l’étude de ce type de publication. On peut notamment citer quelques numéros spéciaux récents de la revue International Journal on Digital Libraries. Parmi les thématiques abordées par les auteurs, nous soulignons celles qui nous semblent orientées vers la formalisation sous forme de données des informations contenues dans les bibliothèques numériques et, plus spécifiquement, l’ouverture des contenus à l’aide des données liées du web sémantique.
- mars 2018 : l’archivage du web est étudié sous l’angle de l’exploitation des contenus ainsi que de leur utilisation collaborative.
Three of the six papers in this special issue concentrate on aids for collecting web content to be archived. The remaining three papers focus on collaboration and exploration of archives, temporal analysis, and use of archived collections (Fox, Klein et Xie 2018, 1).
- novembre 2017 : la revue fait état de travaux sur l’extension d’une technologie liée au web sémantique, soit l’ontologie CIDOC-CRM[9]: « Extending, Mapping and Focusing the CIDOC CRM» (Niccolucci 2017). Il s’agit d’une ontologie de référence pour l’échange d’informations de patrimoine culturel et qui est compatible avec la publication de données liées.
- juin 2017 : le numéro spécial de la revue porte sur différents enjeux de la publication des données de recherche (Research Data Publishing). Les aspects abordés qui sont pertinents ici incluent la représentation sémantique des données (Silvello et al. 2017) et les avantages perçus pour la recherche en sciences sociales (Eynden et Corti 2017).
- mars 2017 : les « cartes de connaissance » et leur utilisation dans la recherche d’information (Knowledge Maps and Information Retrieval – KMIR ) font l’objet du numéro spécial. Les articles se concentrent sur des outils pour soutenir la recherche d’information dans les bibliothèques numériques, notamment ceux qui s’appuient sur des technologies sémantiques. Entre autres, il est question de visualisation et d’exploration de citations pour soutenir des tâches de recherche (Khazaei et Hoeber 2017) ainsi que d’appariement de métadonnées, agrégées de diverses sources, vers un plan de classification (Dewey) (Lin et al. 2017).
Colloques et congrès
Parmi les congrès scientifiques importants sur la question des bibliothèques numériques, on peut compter TPDL[10] (anciennement ECDL) et JCDL. Nous nous permettons d’ajouter à cette liste un colloque francophone, ASBNOR, tenu dans le cadre du congrès de l’ACFAS en 2017.
- En 2017, les sessions du colloque TPDL[11] sont très variées, mais trois des huit portent sur les données et sur les entités (concept lié à celui des données) : Linked Data; Data in DL; Entities. Nous y revenons ci-dessous. Parmi les quatre tutoriels, trois portent également sur les données : Enriching digital collections using tools for text mining, indexing and visualisation; Putting Historical Data in Context: How to use DSpace-GLAM; Enabling Precise Identification and Citability of Dynamic Data – Recommendations of the RDA Working Group on Data citation. De plus, un atelier sur les quatre tenus lors du congrès implique clairement les données : (meta)-data quality workshop, et un deuxième, Modeling Societal Future, les touche en quelque sorte.
- En 2016[12], les données étaient moins présentes, mais une session parmi les dix évoque le web sémantique, par son titre Semantics; les autres sessions touchent divers aspects technologiques ou disciplinaires des bibliothèques numériques : Digital Humanities, DL Design, Search, Specialized Information Services, User Aspects, Web Archives, e-Infrastructures, Multimedia and Time Aspects, DL Evaluation. Les tutoriels en 2016 étaient encore axés sur l’infrastructure technologique : Fedora4, Greenstone3, Text Mining Workflows. Les ateliers offerts aux congressistes en comprenaient un sur les données massives (SoBigData – Social Mining & Big Data Ecosystem), un sur les systèmes en réseau NKOS (Networked Knowledge Organization Systems), un sur les archives web (Alexandria – Foundations for Temporal Retrieval, Exploration and Analytics in web Archives), un sur la science ouverte (Reproducible Open Science) et un sur les images en mouvement dans les bibliothèques numériques (Videos in Digital Libraries). Ainsi, trois portaient sur les données, sur l’ouverture ou sur les liens entre bibliothèques numériques – on le verra, trois caractéristiques du web sémantique.
- En 2015[13], le thème du congrès, Connecting Digital Collections, soulignait l’importance des relations établies entre les bibliothèques numériques (Kapidakis, Mazurek et Werla 2016). C’est un thème auquel nous reviendrons ci-dessous.
Dans le congrès JCDL (Joint Conference on Digital Libraries) tenu en 2017[14], des sessions ont porté sur les collections : Web archives; Scientific collections and libraries; Collection building. D’autres, sur l’exploitation et l’analyse du contenu : Collection access and indexing; Citation analysis; Exploring and analyzing collections; Text extraction and analysis; Classification and clustering. Celles qui retiennent notre attention par contre sont celles sur les aspects sémantiques et relationnels, regroupées sous le titre Semantics and linking.
Le colloque ASBNOR (Analyse la science : les bibliothèques numériques comme objet de recherche)[15] tenu dans le cadre de l’ACFAS en 2017 était axé sur l’exploitation du contenu des bibliothèques numériques (dont plusieurs étaient des bibliothèques numériques de textes scientifiques, mais d’autres aussi des collections muséales). Les titres des sessions du colloque donnent un aperçu des thématiques principales qui réunissaient les chercheurs : Pratiques communicationnelles; Usages et usagers; web sémantique/Données ouvertes liées; Extraction de métadonnées; Fouille de texte; Recherche et découverte d’information. Si les usages, les pratiques et les aspects technologiques divers demeurent des thématiques importantes, le web sémantique et les données liées (ainsi que les métadonnées) prennent une place croissante. Notons enfin que ces communications reflètent les travaux récents qui s’intéressent à l’exploitation du contenu des bibliothèques numériques.
Analyse des tendances récentes
À la lumière de l’étude de ces publications récentes, nous avons décelé quelques thématiques prioritaires retenues par la communauté de recherche des bibliothèques numériques.
- Les données
- Les relations ou les connexions
- L’exploitation du contenu, en particulier la contribution de la sémantique à l’analyse du contenu
Nous reprenons dans la suite spécifiquement un enjeu important récurrent dans ces travaux : les données liées, technologie qui s’inscrit dans celles du web sémantique et qui vient s’insérer graduellement dans les bibliothèques numériques. Cette notion de données liées touche tout à la fois la question du contenu des bibliothèques numériques, les relations établies entre les informations qu’elles contiennent et les relations qui peuvent être établies entre les ensembles de données présents dans différentes bibliothèques numériques. Cela nous semble donc regrouper plusieurs des thématiques récentes de recherche.
Il convient cependant de définir, d’abord, quelques notions de base liées au web sémantique et à ses données liées.
Web sémantique et données liées
Le web se transforme. Ce vaste répertoire de connaissances et informations publiées (Web 1.0) et commentées (Web 2.0) par les internautes risque, si la tendance des travaux du W3C[16] se maintient, de s’enrichir d’une couche de représentation supplémentaire. Le web sémantique (Web 3.0) et les données liées ne visent pas à remplacer le web existant, mais à s’y greffer. Ils représentent un nouveau paradigme de représentation de l’information sur le Web, non plus comme des documents cohérents (des pages web lisibles par l’humain), mais plutôt comme des jeux de données (Linked Open Data) encodées de façon bien particulière, avec des normes de facto préconisées par le W3C (Berners-Lee, Hendler et Lassila 2001).
Les données liées représentent des relations binaires entre un objet et une propriété de celui-ci : des « triplets », encodés selon des standards précis et permettant des traitements automatiques à grande échelle. Par exemple, un triplet pourra relier « Gabrielle Roy » et « Bonheur d’occasion à l’aide de la relation « est-l-auteur-de », et un autre pourra relier « Gandhi » et « Tolstoï » avec la relation « a-écrit-à ». À la place du web existant (dit « Web de documents »), ou plutôt en complément de celui-ci, le web de données ouvre de multiples possibilités de mise en rapport d’informations diverses. Il fait miroiter des possibilités de recherches d’information plus élaborées (parce que basées sur des ensembles d’inférences éventuellement complexes) et de traitements automatiques sophistiqués sur les données. Tout ceci est possible grâce à l’encodage explicite des entités et des relations, qui pourront dès lors être manipulées par des agents informatiques.
Données liées – définition préliminaire
A priori, les données liées sont des données qui sont reliées entre elles par un mécanisme quelconque, qui pourrait être un hyperlien ou une référence explicite (p. ex., des citations ou des références bibliographiques qui relient un ouvrage à un autre). Spécifiquement, dans le cadre du web sémantique, le terme de données liées fait référence à des normes précises de publication de données structurées, de manière à pouvoir lier systématiquement les données entre elles. Ces données sont regroupées en « jeux de données » : on pourra ainsi avoir un jeu de données correspondant aux notices d’une bibliothèque numérique, un autre correspondant aux résultats d’un sondage, un troisième qui collige des données géospatiales, etc. Les types de jeux de données sont très variés et peuvent être issus de milieux scientifiques, commerciaux, documentaires, culturels, gouvernementaux, de réseaux sociaux ou autres.
Chaque jeu de données peut être intéressant en soi; mais d’établir des liens entre certaines de ces données peut être encore plus intéressant, puisque les jeux de données sont ou peuvent être disparates, incomplets, partiellement redondants, et donc complémentaires. En liant les données, différents objectifs peuvent être atteints, dont nous retenons les deux suivants. D’abord, la mise en relation permet de combiner des données pour construire quelque chose de nouveau; par exemple, deux bibliothèques numériques avec des contenus différents (lire, des données différentes) peuvent permettre de reconstituer un portrait plus complet d’une situation donnée. Par exemple, la bibliothèque numérique Les Classiques des sciences sociales couvre avantageusement dans ses documents les personnages et les enjeux liés aux sciences sociales, mais contient peu d’illustrations (photos) et aucun enregistrement sonore mettant en jeu ces personnes; des répertoires d’images ou de vidéos pourraient lui être reliés. Ensuite, l’établissement de relations avec un jeu de données externe peut assurer une visibilité à un premier jeu : les consultations de l’un et l’autre jeux de données en seront accrues.
Plusieurs membres de la communauté scientifique et de diverses communautés professionnelles ont déjà contribué à construire le désormais gigantesque réseau de données liées Linked Open Data (visible à l’adresse http://lod-cloud.net/) : nous pouvons nommer la bibliothèque numérique Europeana, les données bibliographiques diffusées par OCLC (Online Computer Library Center), les vocabulaires contrôlés de la Library of Congress américaine et les données de la BBC Music, pour ne retenir que quelques exemples de cet ensemble de plus de 1160 jeux de données.
Plus près de notre propos, certaines institutions comme la Bibliothèque nationale de France ont publié les données de leur catalogue (en d’autres termes, les métadonnées décrivant leur collection) en données liées selon les standards du web sémantique. Et on voit émerger des initiatives, dans le cadre de projets de recherche, qui visent à extraire de leurs documents (et de leurs travaux) des informations qu’ils encodent en termes de données liées normalisées afin de permettre plus facilement l’exploitation de leurs contenus : les travaux de Sherratt (2015) en histoire, de Cannam et al. (2010) en « music informatics » et de Blanke et al. (2012) en études classiques en sont des exemples.
Tel qu’évoqué dans les travaux présentés dans les revues et les colloques cités ci-dessus, des collections numériques se tournent dorénavant vers ce puissant outil de diffusion de leurs informations. Quand on comprend les avantages généraux de la mise en relation permise par les données liées, on saisit aisément l’intérêt pour une bibliothèque numérique de se joindre à cette entreprise collective.
Web sémantique
Les données liées, nous l’avons dit, représentent une des technologies de base du web sémantique.
L’objectif du web sémantique est d’expliciter la sémantique des informations contenues dans des documents sur le Web, qui sont au départ conçus pour être lus par des êtres humains, afin qu’elles puissent être manipulées de manière adéquate par des agents informatiques.
Les technologies nécessaires pour atteindre les objectifs du web sémantique ont été esquissées par le W3C (https://www.w3.org/2007/03/layerCake.svg). Elles comprennent des technologies utilisées pour représenter l’information, que nous présentons plus en détail ci-dessous, et d’autres pour raisonner sur celle-ci, qui ne sont pas couvertes par le présent article. Nous nous attardons ici sur l’outillage directement pertinent pour la représentation des données, soit les identifiants (URI – Uniform Resource Identifier[17]) et le modèle de données RDF (Resource Description Framework[18]); chacun est brièvement défini ci-dessous.
Le web sémantique repose crucialement sur l’identification et la description d’entités : les entités dignes d’importance, dans les représentations du web sémantique, incluent celles sur lesquelles on peut vouloir exprimer des propriétés ou relations. Pour un document publié, les entités importantes sont sans doute ses métadonnées bibliographiques. Pour une bibliothèque numérique, ce serait d’abord les métadonnées de l’ensemble de sa collection. Dans le cadre d’un projet de recherche, ce sont les personnes, lieux, documents, phénomènes, principes, etc. impliqués dans la recherche. Ces entités peuvent être des ressources présentes sur le web (sites web, bases de données, articles en format numérique, etc.) ou des ressources existant dans le monde physique : personnes en chair et en os, livres imprimés, sites géographiques ou archéologiques, etc. Ceci inclut également toute autre entité abstraite comme une date, un groupe de personnes, une couleur, un rite funéraire, etc.
Les identifiants (URI) sont des chaînes alphanumériques, qui représentent les entités ainsi que les relations de diverses natures qui permettent de relier les entités. Quelques exemples d’URI sont présentés au tableau 1. Il peut s’agir d’URL (Uniform Resource Locator) bien connus, soit des adresses web, ou bien des URN (Uniform Resource Name), soit des noms qui désignent les entités.
| Entités | URI |
| Cours « Indexation de collections numériques » | https://admission.umontreal.ca/cours-et-horaires/cours/SCI-6135 |
| Lyne Da Sylva | http://dasylva.ebsi.umontreal.ca |
| Lyne Da Sylva | http://orcid.org/0000-0003-2530-1048 |
| Guerre et paix | http://catalogue.bnf.fr/ark:/12148/cb31478402c |
| Léon Tolstoï | http://www.isni.org/isni/0000000122424494 |
| Discours sur l’esprit positif | http://classiques.uqac.ca/classiques/Comte_auguste/discours_esprit_positif/Discours_esprit_positif.pdf |
| Analyse et représentation documentaires | urn:isbn:978-2760537453 |
| Michèle Hudon | http://catalogue.bnf.fr/ark:/12148/cb12534437b |
| Chicoutimi | http://sws.geonames.org/5921225/ |
| Montréal | http://sws.geonames.org/6077243/ |
| utopie | http://lod.gesis.org/thesoz/fr/concepts/concept_10060979.html |
| Casques bleus | http://lod.gesis.org/thesoz/fr/concepts/concept_10044376.html |
| Relations | |
| titre (« title ») | http://purl.org/dc/terms/title |
| date de création (« created ») | http://purl.org/dc/terms/created |
| nom de famille (« familyName ») | http://xmlns.com/foaf/0.1/familyName |
| connaît (« knows ») | http://xmlns.com/foaf/spec/#term_knows |
Ces identifiants sont utilisés dans les descriptions informatiques subséquentes pour faire référence à ces entités, notamment les triplets RDF.
Ces triplets servent à encoder les relations entre entités. Ils permettent la représentation de relations très simples (uniquement des relations binaires) comme celles mentionnées ci-dessus. Quelques exemples sont présentés à la figure 1, relatifs à un cours dont le titre est « Indexation de collections numériques ». Pour des raisons de simplicité, nous présentons ces triplets sans recourir au formalisme technique de RDF; on peut néanmoins y voir clairement la structure des triplets. Dans la figure, l’URI http://dasylva.ebsi.umontreal.ca mène à la page web de l’auteur (« creator ») du cours. Un jeu de données liées du web sémantique représente une collection ou un ensemble de tels triplets.
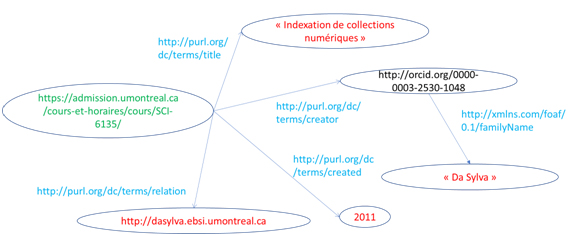
Les technologies du web sémantique comprennent davantage que les données liées (par exemple, les règles de raisonnement que nous avons mentionnées au passage ci-dessus et le langage de requête SPARQL[19] pour faire des recherches dans les jeux de données en RDF). Le réseau Linked Open Data (ou LOD) représente ce que l’on nomme le web de données : « une initiative du W3C … visant à favoriser la publication de données structurées sur le Web, non pas sous la forme de silos de données isolés les uns des autres, mais en les reliant entre elles pour constituer un réseau global d’informations »[20]. Cependant, pour les bibliothèques numériques, la notion de données liées peut être envisagée isolément du reste, quand on a compris que ce sont sur elles que repose la découvrabilité dans le web des données – la possibilité de découvrir de nouvelles informations (de nouveaux jeux de données) grâce aux liens établis entre eux par les relations des triplets RDF.
Il y a une complémentarité entre le web de données et le web de documents (notamment ceux contenus dans les bibliothèques numériques). Les jeux de données encodent de simples relations binaires entre des entités, représentées par des URI. Certains de ces URI désignent des documents entiers, d’autres sont des entités qui sont mentionnées dans ces documents. Les relations encodées sommairement permettent d’établir des liens (peut-être inédits) entre deux documents qui font intervenir les mêmes entités. Ainsi, l’auteur d’un document dans une bibliothèque numérique peut apparaître comme sujet dans un autre document, et cette relation peut être encodée dans un triplet RDF. Ces liens sont une formalisation des liens explicites ou implicites entre documents de collections différentes.
Conséquences de la migration vers l’utilisation des données liées
Les possibilités offertes par l’encodage de données liées ouvrent la voie à des interactions plus élaborées entre des collections :
The advent of the technologies that enhance the exchange of information with rich semantics is of particular interest in the community. Information providers inter-link their metadata with user contributed data and offer new services outlooking to the development of a web of data and addressing the interoperability and long-term preservation challenges (Kapidakis, Mazurek et Werla 2016, 157).
Nous esquissons ci-dessous le travail impliqué dans l’intégration de données liées dans une bibliothèque numérique, ainsi que diverses conséquences d’une telle migration pour les bibliothèques numériques elles-mêmes et pour ceux et celles qui les créent et les utilisent.
Aperçu du travail d’intégration
La première étape, pour diffuser des données liées, c’est d’identifier les données à représenter. Ceci soulève la question : qu’est-ce qu’une donnée? Nous définissons ici « donnée » comme une unité discrète d’information; discrète dans le sens mathématique du terme, c’est-à-dire qui s’exprime en éléments discontinus. Les champs d’une base de données en sont des exemples, comme le sont de petites « molécules » d’informations reliées, en l’occurrence les triplets décrits ci-dessus. Ces unités discrètes s’opposent à l’information diffusée dans des structures continues, comme les phrases de la langue (ou pour des documents non textuels, des images, du son ou de la musique, par exemple).
Alors la question qui se pose est la suivante : quelles sont les données contenues dans une bibliothèque numérique et qu’on voudrait diffuser sous forme de données liées? La question peut être considérée à différents niveaux. Au premier niveau, ces données pourront inclure les métadonnées bibliographiques des documents de la collection : auteurs, titres, dates de publication, numéros ISBN, termes d’indexation le cas échéant, etc.
À un deuxième niveau, il serait intéressant d’ajouter d’autres données qui représentent les entités d’intérêt pour la bibliothèque numérique : par exemple, des personnes, lieux ou périodes temporelles mentionnés dans les documents, ou les thématiques abordées par ceux-ci. C’est ici le contenu de chaque document qui doit être examiné, et non plus simplement ses métadonnées; le processus implique la représentation en éléments discrets, « atomiques », d’entités issues de structures continues. C’est évidemment une opération beaucoup plus exigeante en temps et en expertise humaine (à moins de pouvoir bénéficier de techniques d’extraction automatique). Cette extraction détaillée permettra ultimement d’établir des liens entre les thématiques traitées dans la collection et celles d’une autre bibliothèque numérique.
Puis, les relations entre ces différents « sujets » pourront être encodées : il peut s’agir par exemple de relations entre personnes, ou de liens entre chaque personne et les lieux ou les périodes temporelles pertinents; ou encore, des associations entre ceux-ci et les thématiques récurrentes dans la collection.
Chaque entité et chaque relation devra être représentée par un identifiant (URI), idéalement un identifiant pérenne. Plusieurs répertoires d’identifiants existent à l’heure actuelle; pour les entités, on peut nommer ISNI (International Standard Name Identifier http://www.isni.org/) pour les artistes et les créateurs et ORCID (Open Researcher and Contributor ID[21]) pour les chercheurs (auteurs). Pour les relations, plusieurs ontologies ont été développées, comme le Dublin Core[22] pour l’encodage de métadonnées bibliographiques, FOAF (Friend of a Friend[23]) pour la description des personnes et de leurs relations, ou l’ontologie CIDOC-CRM mentionnée précédemment pour décrire divers aspect du patrimoine culturel grâce à des relations comme « a-utilisé-une-technique-spécifique », « est-composé-de » ou « a-participé-à ».
Ainsi pourra être construit le jeu de données associé à la bibliothèque numérique, destiné à être publié en triplets RDF. La touche finale consiste à relier les entités de la bibliothèque numérique à des entités correspondantes ou reliées qui sont puisées à d’autres jeux de données du LOD : par exemple, les thématiques pourront être reliées à des thésaurus existants publiés en RDF, les œuvres pourront être associées à des versions originales ou à des traductions dans une autre langue et les personnes pourront être associées à des fichiers d’autorité dans différentes bibliothèques nationales à l’aide de VIAF (Virtual Internet Authority File[24]), pour ne donner que quelques exemples.
La figure 2 présente un exemple d’une sélection de triplets qui peuvent être établis à partir d’un document des Classiques des sciences sociales (CSS), le titre « Idéologie et utopie »; c’est la traduction française (1956) d’un ouvrage en allemand (1929) de Karl Mannheim (et qui a été traduit à nouveau en français en 2006, ISBN 978-2-7351-1114-5). La présentation est faite sans identifiants. On a voulu y illustrer que le nom d’une personne pourrait être exprimé soit comme une chaîne de caractères (« Karl Mannheim »), soit comme une entité associée à un prénom et à un nom de famille; les conséquences de chaque choix devraient être explorées, mais cela est hors de notre propos ici.
Le tableau 2 présente les mêmes informations à l’aide d’URI. Des choix ont été faits pour les URI utilisés, à partir de différentes options disponibles. Ceci soulève des questions intéressantes quant à la légitimité des URI retenus, la notion d’autorité et l’équivalence (ou non) d’URI différents pour la même entité, dans des répertoires distincts.
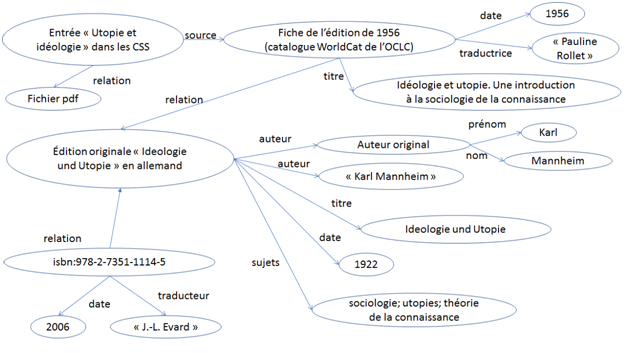
| CSS | http://classiques.uqac.ca/classiques/Mannheim_karl/mannheim_karl.html | http://purl.org/dc/terms/source | http://www.worldcat.org/title/ideologie-et-utopie/oclc/56278594 |
| http://classiques.uqac.ca/classiques/Mannheim_karl/mannheim_karl.html | http://purl.org/dc/terms/relation | http://classiques.uqac.ca/classiques/Mannheim_karl/ideologie_utopie/Ideologie_utopie.pdf | |
| Édition traduite de 1956 | http://www.worldcat.org/title/ideologie-et-utopie/oclc/56278594 | http://purl.org/dc/terms/created | 1956 |
| http://www.worldcat.org/title/ideologie-et-utopie/oclc/56278594 | http://purl.org/dc/terms/contributor | « Pauline Rollet » | |
| http://www.worldcat.org/title/ideologie-et-utopie/oclc/56278594 | http://purl.org/dc/terms/title | Idéologie et utopie. Une introduction à la sociologie de la connaissance | |
| http://www.worldcat.org/title/ideologie-et-utopie/oclc/56278594 | http://purl.org/dc/terms/relation | http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 | |
| Édition originale | http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 | http://purl.org/dc/terms/creator | http://www.isni.org/isni/0000000108748580 |
| http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 | http://purl.org/dc/terms/creator | « Karl Mannheim » | |
| http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 | http://purl.org/dc/terms/title | Ideologie und Utopie | |
| http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 | http://purl.org/dc/terms/created | 1929 | |
| http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 | http://purl.org/dc/terms/subject | http://lod.gesis.org/thesoz/fr/concepts/concept_10034868.html (Ceci correspond à l’étiquette « sociologie » dans le thésaurus Sozialwissenschaften http://lod.gesis.org/thesoz/fr.html). | |
| http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 | http://purl.org/dc/terms/subject | http://lod.gesis.org/thesoz/fr/concepts/concept_10060979.html (Entrée pour « utopie » dans le même thésaurus) | |
| http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 | http://purl.org/dc/terms/subject | théorie de la connaissance | |
| Karl Mannheim | http://www.isni.org/isni/0000000108748580 | http://xmlns.com/foaf/0.1/familyName | Mannheim |
| http://www.isni.org/isni/0000000108748580 | http://xmlns.com/foaf/0.1/givenName | Karl | |
| Édition française 2006 | urn:isbn:978-2-7351-1114-5 | http://purl.org/dc/terms/relation | http://www.worldcat.org/title/ideologie-und-utopie/oclc/924939 |
| urn:isbn:978-2-7351-1114-5 | http://purl.org/dc/terms/created | 2006 | |
| urn:isbn:978-2-7351-1114-5 | http://purl.org/dc/terms/contributor | J.-L. Evard |
Conséquences pour les bibliothèques numériques
Les bibliothèques numériques peuvent grandement bénéficier de l’utilisation des données liées. Quelques utilisations récentes des données liées dans des bibliothèques numériques importantes (spécifiquement, la Bibliothèque nationale de France, Europeana, la bibliothèque du Congrès américain, la British Library et la Bibliothèque nationale d’Espagne) ont été étudiées dans Hallo et al. (2016). Les auteurs y recensent (p. 124) les bénéfices suivants observés suite à l’incorporation de données liées :
- La visibilité des données est améliorée.
- Il est possible d’établir des liens vers d’autres services en ligne.
- La transformation des sujets en SKOS[25] est facilitée.
- La récupération de données ouvertes est améliorée.
- L’interopérabilité est rendue possible sans affecter les modèles de données originaux.
- Il est possible d’interroger des métadonnées liées à partir de plusieurs institutions.
- Cela permet la modélisation d’entités pertinentes liées à une ressource bibliographique, telles que les personnes, les lieux, les événements et thèmes.
- Les annotations des ressources faites par des utilisateurs améliorent leur crédibilité.
Dit autrement, l’ajout de données liées aux bibliothèques numériques entraîne au moins les conséquences suivantes :
- Des avantages pour les utilisateurs et utilisatrices : la possibilité de mise en relation des contenus d’une bibliothèque numérique vers une autre, sur la base d’entités partagées (identifiées à l’aide des URI), et l’extraction facile de données et de métadonnées, grâce à l’encodage formel des relations (ceci dépendra peut-être des possibilités d’exportation et de visualisation des données). On voit dans l’exemple à la figure 2 comment, pour un document donné, cela permet des liens avec des éditions et des catalogues différents.
- Des avantages pour la bibliothèque numérique elle-même : l’ouverture et la mise en relation des données assurent une plus grande visibilité de ses contenus; elles permettent aussi l’accessibilité de ses contenus aux agents informatiques.
- Des contraintes pour les concepteurs et conceptrices : il est nécessaire alors d’ajouter des fonctionnalités nouvelles aux infrastructures existantes (les jeux de données liées), qui exigent des qualifications techniques nouvelles.
Des problèmes ont cependant été rapportés dans les cas étudiés (Hallo et al. 2016, 124‑25) :
- une certaine difficulté à cataloguer des ressources;
- la cohabitation d’un trop grand nombre de vocabulaires pour les mêmes métadonnées;
- une réticence à fournir des données et la difficulté de migrer les données vers de nouveaux modèles;
- un besoin de développer de nouveaux outils pour la transformation des données liées;
- un manque d’experts dans différents domaines pour les transformations;
- un manque d’applications consommant des données liées;
- la perte de richesse des données originales par rapport à celles produites en données liées;
- la définition et le contrôle de la propriété;
- le contrôle de qualité des jeux de données;
- un manque d’indicateurs sur l’utilisation des données liées.
Ce type de difficultés s’aplaniront, on peut l’espérer, à mesure que les différentes bibliothèques numériques s’approprieront la technologie et détermineront de concert les solutions à privilégier.
Conséquences pour les chercheurs et chercheuses
Les conséquences que nous envisageons portent sur les chercheurs et chercheuses en tant qu’utilisateurs de bibliothèques numériques dans leur recherche et aussi en tant que producteurs de nouveaux produits issus de la recherche; certains de ces produits pourront être des « documents augmentés » de liens vers des données externes, alors que d’autres pourront être des jeux de données à publier.
On peut envisager une application axée sur les données qui servirait de base à l’analyse d’un événement historique : par exemple une liste de lieux, de périodes, une base de données de personnes, leurs rôles et les relations entre elles et un certain nombre d’événements (qu’il s’agisse de phénomènes naturels tels que les tremblements de terre ou les phénomènes créés par l’homme tels que les Jeux olympiques d’hiver de 2018). Dès lors, un chercheur peut puiser à ces sources d’information pour contextualiser un événement ou un état de choses spécifique. Un projet de recherche dans cette optique a effectivement été développé (Sherratt 2015), produisant des documents qui intègrent (par des hyperliens) les jeux de données utilisés pour les produire. Diverses possibilités (et conséquences) sont explorées par Michon (2016).
Des données encodées de la sorte, rattachées à divers types de bibliothèques numériques, pourraient être utilisées pour découvrir des relations jusqu’ici non détectées entre des personnes, des lieux ou des événements; les travaux de Gotti et Langlais (2016) en extraction d’information ouverte, qui exploitent les données de Wikipédia et de la plateforme Érudit, représentent un premier pas dans cette direction.
Une démarche de recherche axée sur l’utilisation et la production de données liées (en conjonction avec l’exploitation de documents) amènera plusieurs changements. Nous avons décrit précédemment certaines des conséquences de l’approche web sémantique (et données liées) pour la recherche en sciences humaines (Da Sylva 2017). L’extension à la recherche en sciences sociales et par conséquent aux enseignants et enseignantes de ces disciplines se fait tout naturellement, et nous en reprenons les grandes lignes maintenant.
Des conséquences théoriques
Recherche axée sur les données : « atomisation » de la recherche
La recherche basée sur les données liées favorise l’analyse d’informations fragmentaires, par opposition à des documents entiers ou des survols globaux d’une situation donnée. Les entités individuelles auxquelles sont attribués des identifiants ont une importance prépondérante. Chaque entité participant à l’univers du problème de recherche, de la plus centrale à la plus périphérique, doit être représentée comme un URI, qui ne permet pas a prioride relativiser l’importance de chacune.
Ceci est contraire à l’approche synthétique habituelle de plusieurs disciplines en sciences humaines et sociales (SHS). Dans une approche traditionnelle dans des disciplines telles que l’histoire, la littérature, la linguistique ou l’anthropologie, les principales données étudiées par le chercheur incluent les documents, les phénomènes (par exemple la production de la parole) et les observations (dans les études de terrain par exemple). L’apport important du chercheur est son analyse de ce corpus complexe de données; les relations identifiées et les informations extraites permettent une meilleure compréhension de la question de recherche. Les résultats de la recherche prennent la forme de documents qui fournissent une synthèse ou un récit des données et des phénomènes étudiés. En contraste, dans une approche par données liées, en plus des sources traditionnelles, un chercheur utilise également des jeux de données qui ont été codés par d’autres. Ces ensembles de données sont généralement des silos isolés d’informations (fragmentaires). Ensuite, la contribution du chercheur doit inclure (i) la sélection d’ensembles de données pertinents (donc l’évaluation des ensembles de données existants); (ii) le codage de toute nouvelle donnée découverte par son analyse de l’ensemble formé par les documents, les données et les observations; et enfin (iii) le processus d’ajout de tout nouveau lien pertinent dans les données finales. Parmi les résultats de la recherche, alors, figurera sans doute l’ajout de davantage de données liées. En un mot : alors que l’approche traditionnelle nécessite plus de synthèse et d’abstraction de la part du chercheur, une approche axée sur les données liées intègre une forte composante analytique, nécessaire pour décomposer les observations en données et triplets individuels – ce que nous appelons ici l’« atomisation » des objets de recherche.
Réification des objets de recherche
Il est intéressant de noter que la création d’identifiants et de triplets entraîne la réification d’objets de recherche, c’est-à-dire le fait de conférer un statut d’objet concret à des notions qui peuvent en fait être abstraites (comme, par exemple, « utopie » dans le tableau 1 ci-dessus). Toutes les entités sont représentées par des identifiants : des événements météorologiques, des accords musicaux, le temps, les langues comme le grec, etc. S’il peut sembler normal, pour un chercheur ou une chercheuse, de réifier ses objets de recherche (c’est peut-être un processus naturel dans la recherche), il peut trouver surprenant de traiter les relations comme telles. Comment interprète-t-on « est l-auteur-de » ou « a-écrit-à » en tant qu’entité? Et pourtant, c’est ce qui est fait en quelque sorte quand ces relations sont représentées par un identifiant. Cela peut soulever d’intéressantes nouvelles questions de recherche.
Confusion croissante de la distinction entre données et métadonnées
Comme le suggèrent les exemples ci-dessus, certains triplets sont clairement des métadonnées (par exemple, Tolstoï est l’auteur de Guerre et paix). D’autres introduisent de vraies relations entre deux entités ayant un statut équivalent (par exemple, « Tolstoï a-écrit-à Ghandi »). Pourtant, ils sont traités de la même manière par les triplets RDF. De plus, si des triplets sont créés en extrayant des données à partir de documents primaires, alors, en un sens, tous ces codages deviennent des métadonnées de ce document. Mais si tout devient métadonnée, quelles sont les données? Est-ce que les données disparaissent? Ou est-ce plutôt le concept de métadonnées qui disparaît?
Des conséquences pratiques
Tout comme ça a été soulevé pour les concepteurs et conceptrices des bibliothèques numériques, le passage aux données liées exigera une mise à niveau des qualifications techniques des chercheurs et chercheuses. Un autre aspect que nous avons observé touche à l’effort d’encodage de ces données liées.
Redocumentarisation
La transformation du focus de la recherche non plus vers les documents (lus et produits), mais vers les données (repérées et créées) rappelle la notion de « redocumentarisation » observée pour le document numérique (Pédauque 2007). Le terme fait référence au processus, à la fin du 20e et au début du 21e siècle, de numérisation à grande échelle des documents imprimés existants : la redocumentarisation effectue à nouveau le processus de documentation des savoirs humains – et elle a eu lieu lors de la création de bon nombre de bibliothèques numériques actuelles. Un processus similaire avait eu lieu avec l’invention de l’imprimerie, lorsque les documents manuscrits ont été progressivement imprimés. Ainsi, le codage des triplets RDF est, en fait, un autre processus consistant à prendre des informations existantes (contenues dans des documents narratifs ou non structurés déjà sur le Web) et à les transcoder en une nouvelle forme. La création de chaque triplet nécessite un travail d’analyse fine des documents et la décomposition en ses unités élémentaires. Le résultat de la recherche consiste alors en un modèle analytique (Arsham 2015) constitué de données liées. Cette nouvelle forme est nécessaire pour permettre le traitement sémantique automatisé sophistiqué par les agents logiciels. Étant donné la nature binaire simple des triplets RDF, cette redocumentarisation conduit à l’atomisation de la recherche décrite ci-dessus.
Notons que les efforts requis ne seront pas les mêmes pour toutes les disciplines des sciences humaines et sociales : certaines ont une longueur d’avance, notamment celles qui reposent déjà sur les données (économie, démographie, etc.) ou sur les métadonnées (bibliothéconomie, archivistique, muséologie, etc.). Celles qui sont davantage basées sur les documents (histoire, littérature, etc.) ont un plus long chemin à faire. Et elles sont toutes désavantagées par rapport à la situation en sciences pures, où l’encodage de données liées peut souvent être fait automatiquement à partir de données discrètes obtenues par des appareils de mesure : sondes océanographiques, lectures géologiques, observations astronomiques, etc.
Conséquences pour l’enseignement
Les enseignants doivent s’adapter également, notamment parce que leurs sources documentaires évoluent. Les conséquences principales à prévoir touchent cependant à la formation des étudiants par rapport à ces nouvelles technologies. Pour l’instant, les technologies du web sémantique demeurent l’apanage d’experts. Tout repose en fait sur les outils de visualisation : si les données peuvent être visualisées et interrogées de manière transparente, alors leur utilisation ne devrait pas poser problème. Et on pourra s’attendre à des gains remarquables en apprentissage, ainsi qu’en exploration des contenus des bibliothèques numériques ainsi reliées.
Conclusion
Sur la base d’un examen de publications récentes portant sur les bibliothèques numériques, nous avons relevé une tendance forte : l’inclusion graduelle des données liées, qui sont une technologie du web sémantique. Les bibliothèques numériques pourront dorénavant servir non seulement à héberger des documents,mais aussi à exporter les données qu’elles contiennent et relier, grâce à ces données, diverses bibliothèques numériques entre elles. Nous avons esquissé quelles nous sembleraient être les conséquences les plus importantes de cette évolution pour les bibliothèques numériques elles-mêmes, ainsi que pour ceux et celles qui les créent et les utilisent. Nous attendons maintenant la suite, soit, assurément, une synergie croissante entre les contenus ainsi reliés, ce qui peut certainement être bénéfique. Mais, tel qu’évoqué ci-dessus, cela soulève déjà des questionnements sur les révélations qui émergent de la mise en relation, soit les représentations alternatives de la réalité et la concurrence pour la reconnaissance d’autorité sur les entités représentées, qui susciteront sans doute des débats importants.
Références
Arsham, Hossein. 2015. « Applied Management Science: Making Good Strategic Decisions ».
http://home.ubalt.edu/ntsbarsh/opre640/opre640.htm
Beaudry, Guylaine. 2008. « Les bibliothèques numériques au Québec : état des lieux, enjeux actuels, avenir ». Documentation et bibliothèques 54 (2) : 111‑16.
Berners-Lee, Tim, James Hendler et Ora Lassila. 2001. « The Semantic web ». Scientific American, 28‑37.
Blanke, Tobias, Gabriel Bodard, Michael Bryant, Stuart Dunn, Michael Hedges, Michael Jackson et David Scott. 2012. « Linked data for humanities research: The SPQR experiment ». Dans 2012 6th IEEE International Conference on Digital Ecosystems and Technologies (DEST), 1-6.
https://doi.org/10.1109/DEST.2012.6227932
Borgman, Christine L. 2000. « Digital libraries and the continuum of scholarly communication ». Journal of Documentation 56 (4): 412‑30.
https://doi.org/10.1108/EUM0000000007121
Cannam, Chris, Mark Sandler, Michael O. Jewell, Christophe Rhodes et Mark d’Inverno. 2010. « Linked Data and You: Bringing Music Research Software into the Semantic Web ». Journal of New Music Research 39 (4): 313‑25.
https://doi.org/10.1080/09298215.2010.522715
Da Sylva, Lyne. 2017. « Vers les données liées : conséquences théoriques et pratiques pour les sciences humaines ». Dans Digital Humanities 2017 Conference Abstracts, édité par Rhian Lewis, Cecily Raynor, Dominic Forest, Michael Sinatra et Stéfan Sinclair, 213‑15. Université McGill, Montréal.
https://dh2017.adho.org/abstracts/DH2017-abstracts.pdf
Da Sylva, Lyne. 2013. « Genèse et description des bibliothèques numériques ». Documentation et bibliothèques 59 (3): 132‑45.
https://doi.org/10.7202/1018843ar
Eynden, Veerle Van den et Louise Corti. 2017. « Advancing Research Data Publishing Practices for the Social Sciences: From Archive Activity to Empowering Researchers ». International Journal on Digital Libraries 18 (2): 113‑21.
https://doi.org/10.1007/s00799-016-0177-3
Fox, Edward A., Martin Klein et Zhiwu Xie. 2018. « Guest Editors’ Introduction to the Special Issue on web Archiving ». International Journal on Digital Libraries 19 (1): 1-2.
https://doi.org/10.1007/s00799-016-0203-5
Gotti, Fabrizio et Philippe Langlais. 2016. « Harnessing Open Information Extraction for Entity Classification in a French Corpus ». Dans Advances in Artificial Intelligence, édité par Richard Khoury et Christopher Drummond, 9673: 150-61. Cham: Springer International Publishing.
https://doi.org/10.1007/978-3-319-34111-8_20
Hallo, María, Sergio Luján-Mora, Alejandro Maté et Juan Trujillo. 2016. « Current State of Linked Data in Digital Libraries ». Journal of Information Science 42 (2): 117‑27.
https://doi.org/10.1177/0165551515594729
Kapidakis, Sarantos, Cezary Mazurek et Marcin Werla. 2016. « Editorial for the TPDL 2015 Special Issue on TPDL 2015 ». International Journal on Digital Libraries 17 (3): 157‑58.
https://doi.org/10.1007/s00799-016-0190-6
Khazaei, Taraneh et Orland Hoeber. 2017. « Supporting Academic Search Tasks through Citation Visualization and Exploration ». International Journal on Digital Libraries 18 (1): 59‑72.
https://doi.org/10.1007/s00799-016-0170-x
Lin, Xia, Michael Khoo, Jae-Wook Ahn, Doug Tudhope, Ceri Binding, Diana Massam et Hilary Jones. 2017. « Mapping Metadata to DDC Classification Structures for Searching and Browsing ». International Journal on Digital Libraries 18 (1): 25‑39.
https://doi.org/10.1007/s00799-016-0197-z.
Michon, Philippe. 2016. « Vers une nouvelle architecture de l’information historique : L’impact du web sémantique sur l’organisation du Répertoire du patrimoine culturel du Québec ». Mémoire de maîtrise, Sherbrooke: Université de Sherbrooke.
http://savoirs.usherbrooke.ca/bitstream/handle/11143/8776/Michon_Philippe_MA_2016.pdf?sequence=8&isAllowed=y
Niccolucci, Franco. 2017. « Extending, Mapping, and Focusing the CIDOC CRM ». International Journal on Digital Libraries 18 (4): 251‑52.
https://doi.org/10.1007/s00799-016-0198-y
Pédauque, Roger T. 2007. La Redocumentarisation du Monde. Paris: Éditions Cépadues.
Sherratt, Tim. 2015. « Stories for Machines – Data for Humans ». DISCONTENTS working for the triumph of content over form, ideas over control, people over systems. 10 avril 2015.
http://discontents.com.au/stories-for-machines-data-for-humans/
Silvello, Gianmaria, Georgeta Bordea, Nicola Ferro, Paul Buitelaar et Toine Bogers. 2017. « Semantic Representation and Enrichment of Information Retrieval Experimental Data ». International Journal on Digital Libraries 18 (2): 145-72.
https://doi.org/10.1007/s00799-016-0172-8
- http://www.erudit.org ↵
- http://www.persee.fr/web/guest ↵
- http://classiques.uqac.ca/ ↵
- http://www.gutenberg.org ↵
- http://www.ina.fr/ ↵
- http://europeana.eu/portal/fr ↵
- http://www.civilisations.ca/musee-virtuel-de-la-nouvelle-france/introduction ↵
- http://www.canadiana.ca/ ↵
- CIDOC (ICOM's International Committee for Documentation) Conceptual Reference Model, http://www.cidoc-crm.org/sites/default/files/cidoc_crm_version_5.0.4.pdf ↵
- International Conference on the Theory and Practice of Digital Libraries ↵
- http://www.tpdl.eu/tpdl2017/ ↵
- http://www.tpdl2016.org/ ↵
- http://tpdl2015.info/ ↵
- http://2017.jcdl.org/ ↵
- http://dasylva.ebsi.umontreal.ca/ACFAS2017/accueil.html ↵
- World Wide web Consortium (https://www.w3.org/). ↵
- https://tools.ietf.org/html/rfc3986 ↵
- https://www.w3.org/RDF/ ↵
- https://www.w3.org/TR/sparql11-overview/ ↵
- https://fr.wikipedia.org/wiki/Web_des_données ↵
- https://orcid.org/ ↵
- http://dublincore.org/ ↵
- http://www.foaf-project.org/ ↵
- http://viaf.org/ ↵
- Simple Knowledge Organization System, un formalisme recommandé par le W3C pour encoder les langages d’indexation (https://www.w3.org/2004/02/skos/). ↵

{kind=link}